 U
U経営情報システムの科目でSQLが出てきたとき、最初は「プログラミングみたいで難しそう」と思ってしまいました。
でも実際に学んでみると、SQLは特定の構文を覚えれば読み解けるようになる、比較的パターンの決まった分野だとわかりました。
今回は、試験に出やすいポイントを中心に、SQLの基礎を図解で整理してみます。
中小企業診断士試験の科目の中でも、「経営情報システム」は苦手科目になりやすい分野として知られています。とりわけSQLに関する問題を見ると、アルファベットや記号が並んでいるため、プログラミングのように感じてしまい、「IT経験がない自分には難しい」と考えてしまう受験生も少なくありません。
しかし、この認識は大きな誤解です。SQLは高度なプログラムを書くための技術ではなく、データを取り出すためのルールを定めた言語に過ぎません。基本構造を理解すれば、むしろ試験では得点しやすい論点になります。
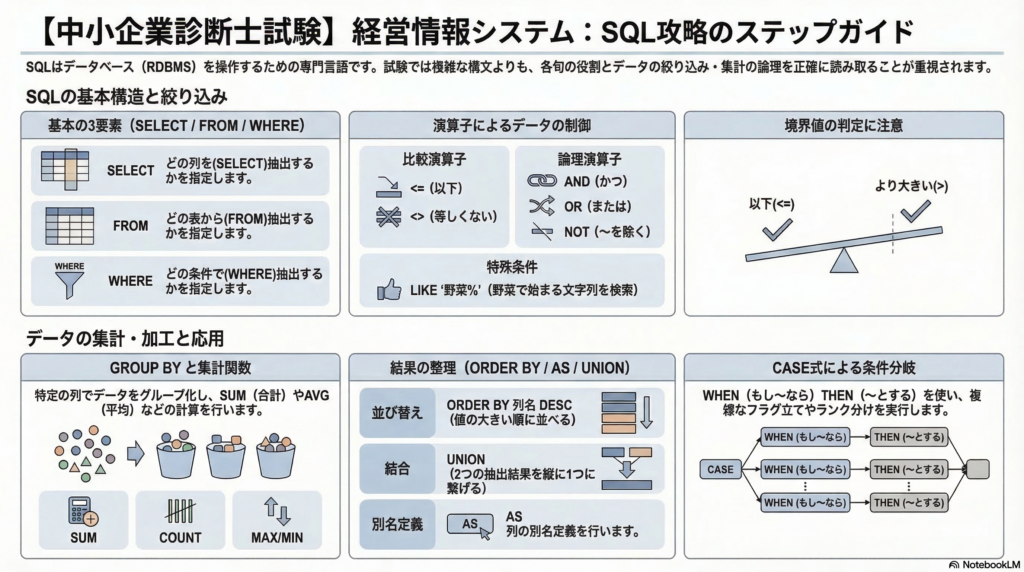
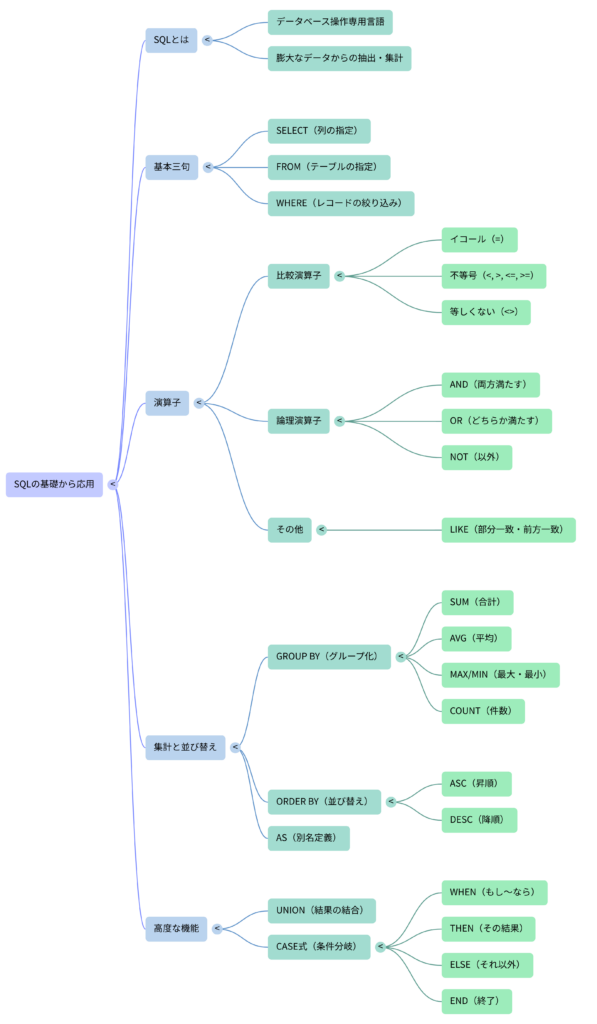
出題パターンは比較的安定しており、SELECT・FROM・WHEREといった基本構造や、条件分岐、テーブルの結合といったポイントを理解していれば、多くの問題を読み解くことができます。ここでは、SQLを初めて学ぶ受験生でも理解できるように、仕組みと重要ポイントを具体例と図表を交えながら整理します。
データベースとSQLが必要な理由
SQLを学ぶ前に、まず「なぜデータベースが必要なのか」を押さえておくと、SQLの役割が見えてきます。
企業では売上・在庫・顧客情報などが毎日追加され続けます。Excelでは限界がある大量データを管理するのがデータベースで、そこから「必要な情報だけを取り出す」ための言語がSQL(Structured Query Language)です。
U最初は「エンジニアが使う特殊な言語」というイメージがあったのですが、SQLは「どのテーブルから・どの条件で・何を取り出すか」を日本語に近い感覚で書ける言語なんですね。構文を覚えてしまえば、あとはパターン認識で解けるようになってきました。
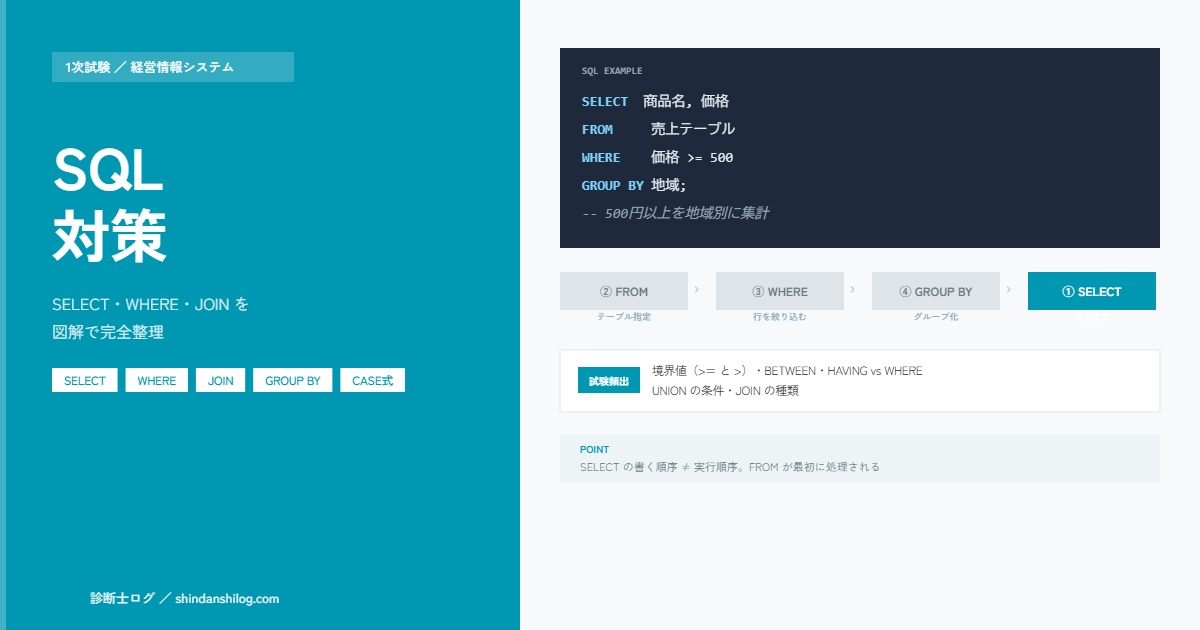
SQLの基本構造|SELECT・FROM・WHERE の3要素
SQLのほぼすべての文は、次の3つのキーワードで構成されています。この骨格を頭に入れておくと、複雑な文を見ても分解して読めるようになります。
FROM 売上テーブル — ② どのテーブルから
WHERE 価格 >= 500; — ③ どの条件で絞り込むか
SQLは書いた順番ではなく、FROM → WHERE → SELECT の順で処理されます。「まずテーブル全体を指定し、条件で行を絞り込み、最後に表示する列を選ぶ」という流れです。
WHERE句と比較演算子|試験で差がつく境界値
次のような飲料の売上テーブルを例に、WHEREの使い方を確認します。
| 商品ID | 商品名 | 価格 | 販売数 | 地域 |
|---|---|---|---|---|
| 001 | コーヒー | 300 | 120 | 東京 |
| 002 | 緑茶 | 200 | 85 | 大阪 |
| 003 | 紅茶 | 500 | 60 | 東京 |
| 004 | ほうじ茶 | 350 | 40 | 名古屋 |
| 005 | 抹茶ラテ | 600 | 95 | 大阪 |
| 演算子 | 意味 | 例 |
|---|---|---|
| = | 等しい | 地域 = ‘東京’ |
| <> | 等しくない | 地域 <> ‘東京’ |
| > | より大きい(その値は含まない) | 価格 > 500 |
| >= | 以上(その値を含む) | 価格 >= 500 |
| < | より小さい(その値は含まない) | 販売数 < 100 |
| <= | 以下(その値を含む) | 販売数 <= 100 |
| BETWEEN A AND B | A以上B以下(両端を含む) | 価格 BETWEEN 300 AND 500 |
| IN (…) | リスト内のいずれかに一致 | 地域 IN (‘東京’,’大阪’) |
| LIKE ‘〜%’ | 前方一致(% は任意の文字列) | 商品名 LIKE ‘抹茶%’ |
| IS NULL | 値が空(NULL)である | 販売数 IS NULL |
価格 >= 500(以上)→ 500円の商品は含まれる価格 > 500(より大きい)→ 500円の商品は含まれないBETWEEN も両端を含みます。
BETWEEN 300 AND 500 は 300・350・500 の3件が該当します。
SELECT 商品名, 価格
FROM 売上テーブル
WHERE 価格 >= 500;
— 東京または大阪の商品
SELECT 商品名, 地域
FROM 売上テーブル
WHERE 地域 IN (‘東京’, ‘大阪’);
集計関数と GROUP BY|地域別・商品別の集計
SQLでは行を集計するための関数が使えます。GROUP BY と組み合わせると、グループ別の集計が可能です。
| 関数 | 内容 | 使用例 |
|---|---|---|
| COUNT(*) | 行数を数える | COUNT(*) → 件数 |
| SUM(列名) | 合計値 | SUM(販売数) → 総販売数 |
| AVG(列名) | 平均値 | AVG(価格) → 平均価格 |
| MAX(列名) | 最大値 | MAX(価格) → 最高価格 |
| MIN(列名) | 最小値 | MIN(価格) → 最低価格 |
SELECT 地域, SUM(販売数) AS 販売数合計
FROM 売上テーブル
GROUP BY 地域;
— 合計100件以上の地域のみ(HAVING はGROUP BY後の絞り込み)
SELECT 地域, SUM(販売数) AS 販売数合計
FROM 売上テーブル
GROUP BY 地域
HAVING SUM(販売数) >= 100;
HAVING:GROUP BY の後でグループを絞り込む(集計結果に条件を適用)
WHERE SUM(販売数) >= 100 はエラーになります。集計関数はWHEREでは使えません。
UWHERE と HAVING の使い分けは最初に混乱しやすいポイントでした。「WHERE は行を絞る・HAVING はグループを絞る」と言葉で整理しておくと、試験問題を読むときに落ち着いて判断できるようになりました。
CASE式|条件によって表示内容を切り替える
CASE式は、条件によって返す値を切り替える機能です。顧客の購入金額によってランク分けするような場面で使われます。
CASE
WHEN 価格 >= 500 THEN ‘高価格帯’
WHEN 価格 >= 300 THEN ‘中価格帯’
ELSE ‘低価格帯’
END AS 価格帯
FROM 売上テーブル;
| 商品名 | 価格 | 価格帯(CASE式の結果) |
|---|---|---|
| コーヒー | 300 | 中価格帯 |
| 緑茶 | 200 | 低価格帯 |
| 紅茶 | 500 | 高価格帯 |
| ほうじ茶 | 350 | 中価格帯 |
| 抹茶ラテ | 600 | 高価格帯 |
JOIN|2つのテーブルを横につなぐ
実際の業務では、データは複数のテーブルに分かれて管理されています。JOINを使うと、共通の列(キー)をもとに2つのテーブルを横方向に結合できます。
| 注文ID | 商品ID | 数量 |
|---|---|---|
| A001 | 001 | 3 |
| A002 | 003 | 1 |
| A003 | 001 | 2 |
| 商品ID | 商品名 | 価格 |
|---|---|---|
| 001 | コーヒー | 300 |
| 002 | 緑茶 | 200 |
| 003 | 紅茶 | 500 |
FROM 売上テーブル s
INNER JOIN 商品テーブル p
ON s.商品ID = p.商品ID;
| 注文ID | 商品名 | 数量 | 価格 |
|---|---|---|---|
| A001 | コーヒー | 3 | 300 |
| A002 | 紅茶 | 1 | 500 |
| A003 | コーヒー | 2 | 300 |
INNER JOINは両方のテーブルに存在するデータのみを結合します。一方にしか存在しないデータは結果に含まれません。LEFT JOINを使うと、左テーブルのデータをすべて残し、一致しない右テーブルの列はNULLになります。
U「どちらが左・右か」は、FROM句に書いたテーブルが左、JOIN句に書いたテーブルが右、と覚えると整理しやすくなりました。
UNION|テーブルを縦に積み上げる
UNIONは2つのSELECT文の結果を縦方向に結合します。例えば東京店と大阪店の売上データが別テーブルで管理されている場合、UNIONで一つにまとめられます。
UNION
SELECT 商品名, 販売数 FROM 大阪店;
② 対応する列の順序が一致していること
③ 対応する列のデータ型が一致していること
列名の一致は不要です(結果の列名は最初のSELECT文の列名が使われます)。
また UNION は重複行を除去しますが、UNION ALL は重複を含めてすべての行を返します。
コンビニのレジで考えてみると
U「SQLって抽象的でイメージが持ちにくいな」と感じていたとき、コンビニのデータ管理を思い浮かべてみたら少しすっきりしました。
→ WHERE 商品名 = ‘おにぎり’ AND 数量 >= 3
→ GROUP BY カテゴリ + SUM(売上金額)
→ UNION で3つの店舗テーブルを縦に結合
日常の「知りたいこと」がそのままSQLの構造に対応しています。試験問題を見るときも、「このSQLは日本語でいうと何を聞いているのか」と置き換えて考えると、正誤の判断がしやすくなります。
試験問題で確認してみましょう
FROM 商品テーブル
WHERE 価格 BETWEEN 300 AND 500;
- ア 1件
- イ 2件
- ウ 3件
- エ 4件
- ア 結合する両方のSELECT文の列数が一致していること
- イ 対応する列のデータ型が一致していること
- ウ 両方のテーブルに同じ列名が存在すること
- エ UNIONは重複した行を自動的に除去する
まとめ
- SQLはデータベースからデータを取り出す言語。処理順序は FROM → WHERE → SELECT
- SELECT・FROM・WHERE の3要素がSQLの骨格。この構造を読めれば大半の問題に対応できる
- 比較演算子の境界値(>= と >、BETWEEN の両端を含む)は試験頻出。1点差に直結する
- 集計関数(SUM・AVG・COUNT等)は GROUP BY と組み合わせてグループ別集計に使う
- WHERE はGROUP BY の前・HAVING はGROUP BY の後の絞り込み。集計関数はWHEREでは使えない
- CASE式は WHEN〜THEN〜ELSE〜END の構造で、条件に応じて返す値を切り替える
- INNER JOIN は共通キーでテーブルを横に結合。両方に存在するデータのみ取り出す
- UNION はテーブルを縦に結合。列数・順序・データ型の一致が必要。列名の一致は不要
USQLは最初こそ記号の羅列に見えますが、「どこから・何を・どんな条件で」という問いに答える構造だとわかると、問題を落ち着いて読み解けるようになりました。まずは SELECT・FROM・WHERE の流れを体に染み込ませるところから始めてみてください。同じように学び始めた方のお役に立てましたら嬉しいです。